“现在是企业应用Hadoop的最佳时机。”Hortonworks公司首席技术官Jeff Markham在11月底举行的2013中国Hadoop技术峰会上演讲时表示。在本次峰会上,Hadoop进入2.0时代成了人们谈论的焦点。Jeff Markham表示,Hadoop 2.0拥有更强大、更广泛的符合企业用户需求的新特性,弥补了Hadoop 1.0的不足之处,更符合企业用户的需求。
Hadoop改头换面
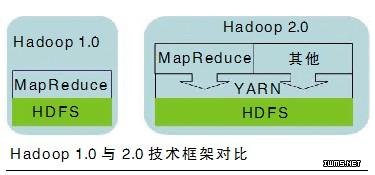
Jeff Markham在介绍Hadoop 2.0的新特性时,记者听到身后有人窃窃私语:“你看,Hadoop 2.0的框架中多了几个奇怪的功能模块。”是的,这些功能模块中最重要的就是YARN。YARN其实是一个资源管理器,它从某种程度上说颠覆了Hadoop的数据处理核心MapReduce,能让用户以与批处理完全不同的新的交互方式来运行Hadoop。众所周知,Hadoop的设计初衷是为了搜索和索引Web网页,而负责操控数据的MapReduce擅长处理和分析非结构化或半结构化的数据,比如日志文件等,但并不适合处理所有类型的数据。随着数据量的增长以及数据复杂性的增加,人们更希望能够在一个集群中处理多种类型的应用程序。这也是Hadoop 2.0诞生的背景。
有人认为,YARN本质上就是Hadoop的新操作系统,它突破了MapReduce的性能瓶颈。Hadoop与YARN的组合更适合企业大数据的应用。YARN的设计思想是将资源管理与作业调度/监控功能分离,其架构实现是通过一个全局的ResourceManager与若干个面向具体应用程序的ApplicationMaster的组合,其中ResourceManager负责将资源分配到各个应用程序,而ApplicationMaster负责运行和监控任务。Jeff Markham表示:“加入YARN这一管理层,让Hadoop可以更好地满足企业级用户对大数据平台的需求。我们公司从安全、管理、配置等多个层面已经为Hadoop 2.0进入企业做好了准备。”
Hadoop 2.0已经不是一个设想,而是实实在在的解决方案。中国本土的大数据公司星环信息科技(上海)有限公司(以下简称星环科技)就在峰会上宣布,正式推出融合Spark与Hadoop 2.0的大数据平台产品Transwarp Data Hub。“企业用户的一个共同想法是,更高效地处理更大量的数据,同时降低时延。”星环科技联合创始人、CTO孙元浩介绍说,“以前,针对不同数量级的数据,人们会采用不同的处理技术,比如内存技术、索引技术以及一些性能优化技术等。Transwarp Data Hub的一个最突出的优势是,可以在一个平台上处理从GB级到PB级的数据。”
正是因为Transwarp Data Hub具备了这样的能力,所以它的应用范围十分广泛,包括离线分析、统计与挖掘、在线存储以及在线的基于内存的高速分析等。Transwarp Data Hub将数据集成/ETL、大数据存储和在线服务系统、基于内存的高效计算引擎、高性能SQL、统计分析和机器学习等融为一体,实现了性能上的突破。用孙元浩的话说,Transwarp Data Hub具有“闪电”般的速度,其速度比开源Hadoop 2.0快10~100倍。此外,Transwarp Data Hub还具有强大的分析能力,并与Hadoop生态系统全面兼容。
以Transwarp Data Hub为核心,星环科技还与许多大数据厂商进行了合作,包括Revolution R、Informatica、Tableau等,将这些厂商的数据处理与分析工具进行整合,构成了完整的大数据平台。
降低应用门槛
由于Hadoop本身的复杂性,以及企业中缺少相关的大数据专业技术人员,Hadoop若想在企业用户中得到快速普及其实并不容易。因此,很多IT厂商纷纷向Hadoop抛出“橄榄枝”,有的提供基于Hadoop的硬件解决方案,有的则推出了Hadoop软件的商业发行版,其目的只有一个,就是降低Hadoop的应用门槛。
在本次峰会上,许多知名IT厂商,包括英特尔、VMware、华为等以及众多电信运营、互联网企业都现身说法,为Hadoop在中国的推广站脚助威。英特尔亚太研发有限公司总经理何京翔表示,除了发布Hadoop商业发行版以外,英特尔从硬件(包括处理器、固态硬盘等)、安全性、管理和优化等多个角度对Hadoop提供全方位支持,目的就是让Hadoop更能满足企业用户的需要。
Nutch集成slor的索引方法介绍? ?* 建立索引? ?* @param solrUrl solr的web地址? ?* @param crawlDb 爬取DB的存放路径:\crawl\crawldb
我们想了个办法:把海量数据分成小块,让一台机器处理一小块数据,所有的机器同时工作。最后把结 果汇总起来。这就是“并行计算”。hadoop中的MapReduce就是专门用来做分布式计算的并行处理框架。hadoop就是用来解决大数据的存储和计算的。
以Hadoop Tutorial为主体带大家走一遍如何使用Hadoop分析数据!MapReduce框架由一个Jobracker(通常简称JT)和数个TaskTracker(TT)组成(在cdh4中如果使用了Jobtracker HA特性,则会有2个Jobtracer,其中只有一个为active,另一个作为standby处于inactive状态)。JobTr
重谈下MapReduce框架中用户经常使用的一些接口或类的详细内容。了解这些会极大帮助你实现、配置和优化MR任务。当然javadoc中对每个class或接口都进行了更全面的陈述,这里只是一个指引教程。
hadoop常见问题解决:WARN mapred.LocalJobRunner: job_local910166057_0001o
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。










